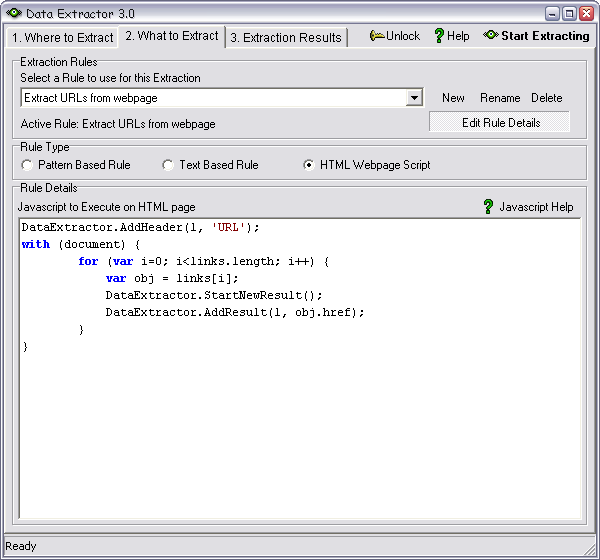
2. What to Extract
After you have chosen where to extract from use the second tab to specify what
to extract. The Data Extractor comes with six predefined rules that you can use
to extract common pieces of data that you may be looking for:
| Email Address |
| Fully Typed Internet URLs |
| U.S. Phone Numbers |
| Extract Image details from webpage |
| Extract URLs from webpage |
| Extract Form Field details from webpage |
These rules can be used simply by selecting them and clicking the 'Start Extracting'
button. You can also add new rules by clicking the 'New' button and selecting the
'Edit Rule Details' button.
Details on how to construct your own rules follow. All rules are automatically saved as you create them.
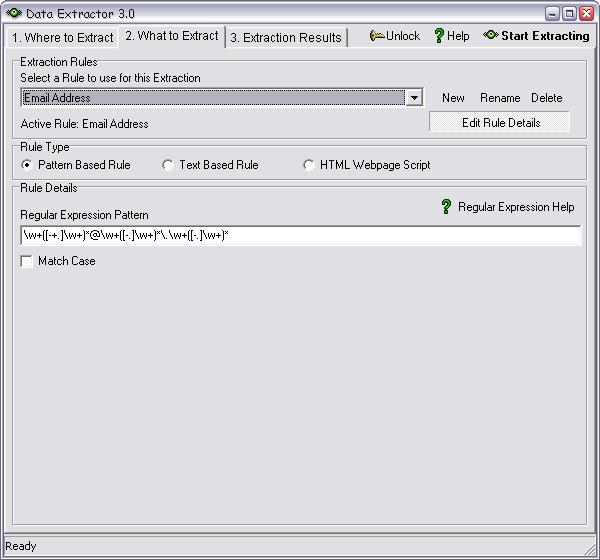
Pattern Based Rule
This option uses regular expressions, which is an advanced pattern matching
language, to match information. You can specify your own regular expression;
to learn more about the regular expression language you can take a look at
this tutorial.
You may choose the 'Match Case' option to ignore or include uppercase and lowercase matching.
 Text Based Rule
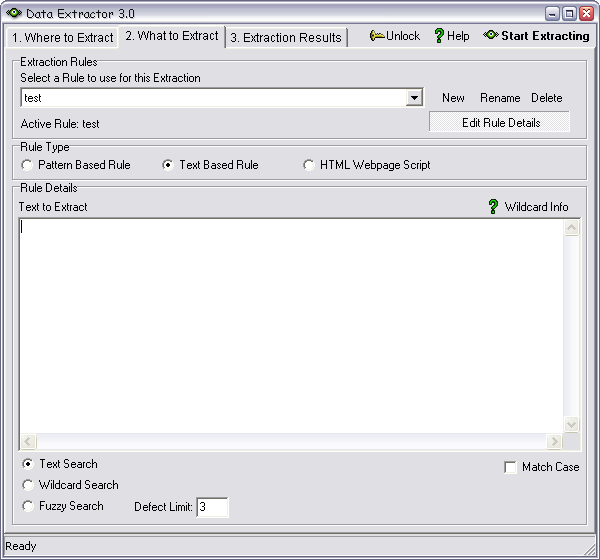
Text Based Rule
If you want to search for exact text then specify the 'Text Based Rule' option.
Specifying 'Match Case' will ensure that your text is matched only when the
uppercase and lowercase characters match.
To match your text using wildcards you can specify a wildcard search using
the following options:
| ? | match any single character |
| * | match any substring, including an empty string |
| # | match any numeric character (0 to 9) |
| @ | match any alpha character (A to Z, or a to z) |
| $ | match any alphaNumeric character |
| ~ | match any non-alphaNumeric, non-space character |
For example, performing a wildcard search for 'f?nd' will match 'fend', 'find' and 'fond'.
You can also specify a fuzzy search. Fuzzy searches have a defect limit, which specifies how fuzzy the fuzzy search should be. For example a fuzzy search for 'found' will match 'bound' with defect limit of 1. Extending the defect limit to 3 will match 'freed' as there are three character changes between 'found' and 'freed'.
 HTML Webpage Script
HTML Webpage Script
If you're extracting from the web, or any HTML files then you may use an HTML Webpage
Script to extract data. This option is the most flexible, and does require that
you're familiar with JavaScript. The script that you enter will be executed directly
on the webpage, so you will have access to the Document Object Model (DOM) in exactly
the same manner you would if you were writing javascript on an HTML page.
The Data Extractor allows for several additional javascript commands that control the Data Extractor:
| DataExtractor.QuitExtraction(); |
After the current rule has completed Extraction will halt. |
| DataExtractor.SetColumns(columns); |
Sets the number of columns in the extraction grid. |
| DataExtractor.AddResult(column, data); |
Adds the result text specified in data, at the column number column. |
| DataExtractor.AddHeader(column, data); |
Specifies the column header text specified in data, at the column number column. |
| DataExtractor.StartNewResult(); |
Instructs the Data Extractor to start a new result. This should be specified before any results are added. |
| DataExtractor.ShowError(errorText); |
Reports an error to the user specified as errorText. This does not halt the extraction. |
| DataExtractor.ClearResults(); |
Clears all results from the Extraction grid. |
| DataExtractor.AddURL(URL); |
Adds the specified URL to the 'Files for Extraction' list. If the Data Extractor is using
that list to extract, then the URL that is being added will also be extracted. This command can be used to create
custom webpage spiders. |
If you require help making scripts please
contact us for our rule making service.